- Published on
Building Trust in AI: A Guide to Reliability and Testing for LLM Applications with LangSmith
- Authors

- Name
- Dan Orlando
- @danorlando1
As large language models (LLMs) continue to advance, integrating them into real-world applications comes with immense responsibility. Users want reassurance that these AI systems are safe, reliable, and trustworthy. This blog post outlines critical strategies for reliability and testing that instill confidence in LLM applications. We'll explore traceability, user feedback loops, dataset curation and evaluation, vulnerability assessments, and monitoring - all crucial elements for developing robust AI that meets the highest standards. By implementing these best practices, we can build trust and drive widespread adoption of LLMs that enrich people's lives.
Note: this article uses LangSmith as the system of choice for tracing LLM run sequences and collecting datasets largely because of it's neat integration with LangChain, but a whole slew of viable options have emerged in recent months. LangFuse is an excellent open source alternative, for example.
Reliability and Testing
For AI solutions to be successful, there must be a commitment to reliability and superior performance. This is achieved through the implementation of robust reliability measures, carefully crafted to safeguard the integrity of AI applications and foster confidence among users and stakeholders.
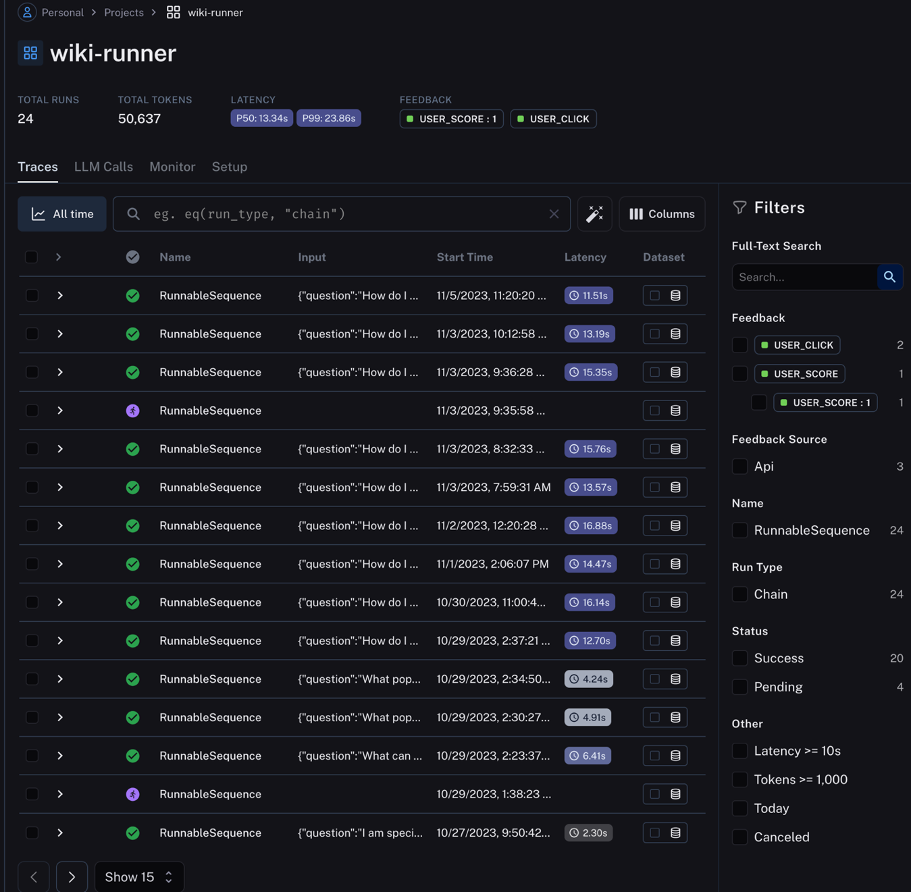
It's crucial to understand the internal mechanisms of our AI systems behind the scenes, which is why LangSmith is integrated into our proof-of-concept applications. As depicted in the image below, LangSmith collects traces from the DevOps Wiki Explorer application, providing a transparent view into the AI's thought process.
User Feedback Loops
Integration of user feedback supports continuous improvement and ensures user needs drive the evolution of AI applications. User feedback mechanisms should be implemented into prototypes and proof-of-concept applications, allowing for efficient data collection and subsequent analysis from the very beginning. Developers should then be encouraged to make legitimate inquiries and trigger the feedback mechanisms for every run, even when testing features unrelated to LLM output.
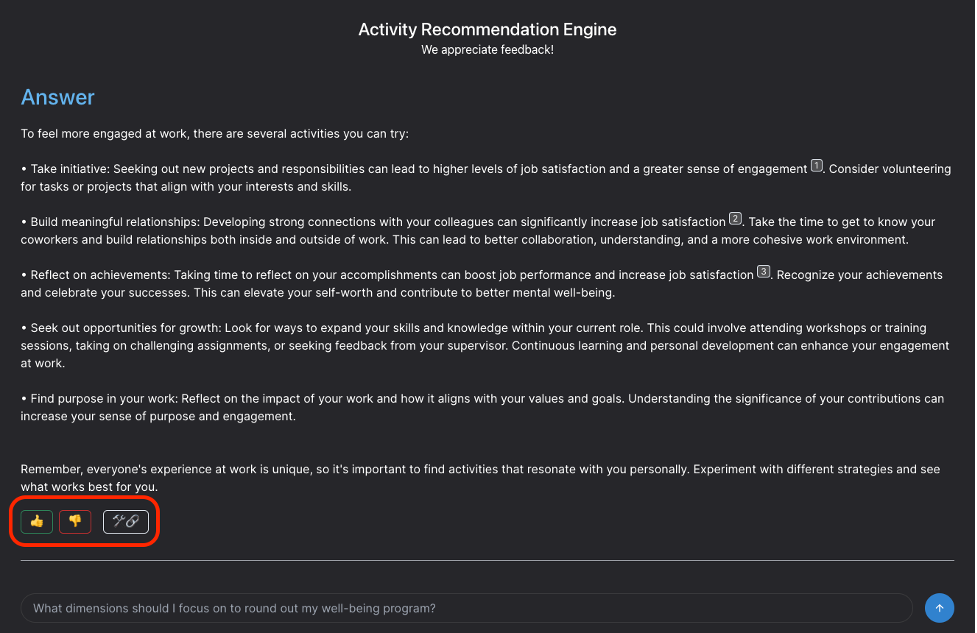
Negative feedback triggers a deep dive into the run sequence, allowing us to pinpoint and address the root cause of unsatisfactory responses. LangSmith's nested traces give us insight into the sequence of calls for each operation, enabling precise identification and rectification of errors. For example, in the figure below, we are looking at the information retrieved from the semantic search that was injected into the prompt's context window to find out if the information was in fact relevant to what was asked.
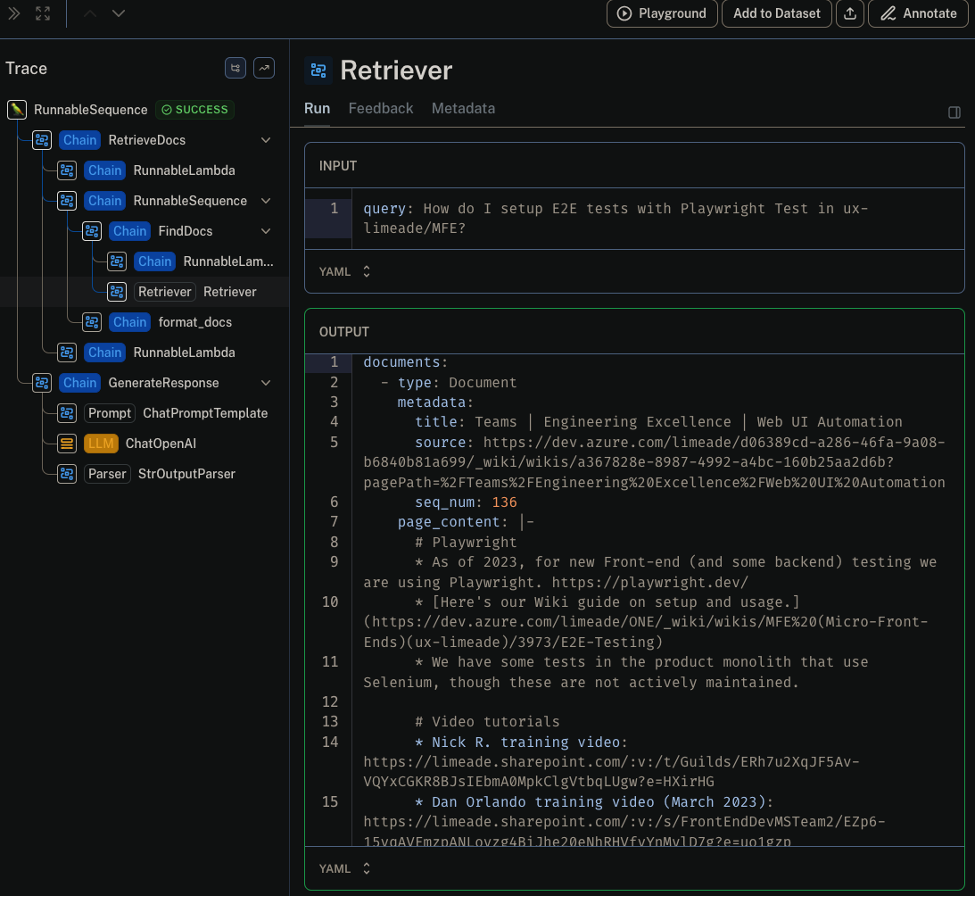
By monitoring interactions at the prompt level, we ensure that the AI's responses align with intended outcomes.
Dataset Curation, Batch Testing, and Evaluation
Runs that receive positive feedback scores are used to curate datasets that can then be used for fine-tuning a (usually smaller) model. We can also use these datasets to experiment and test new prompts, chains, and agents by running batch jobs against them. In this scenario, the input queries from the dataset are run against the new prompt, chain, or agent and a new dataset is generated with the new outputs.
We can have AI compare the outputs from the initial data set against the new outputs and provide a detailed report of the result along with a comprehensive scoring table. There are open-source models available that have been trained specifically for this purpose. Leveraging AI to evaluate our systems ensures a consistently high standard of quality control. The following diagram illustrates this flow.
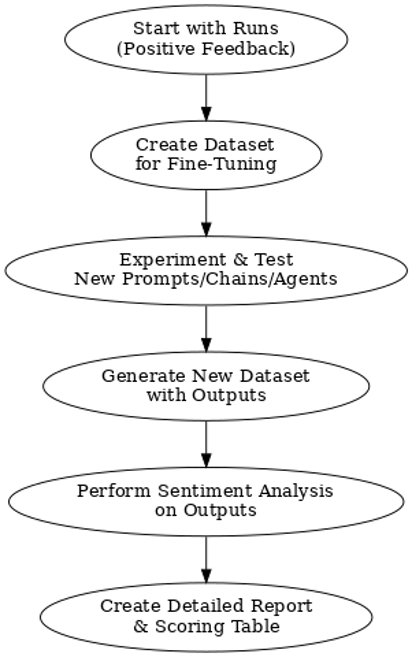
Dataset curation is a crucial pre-requisite to eventually running your own models independently. A popular method for drastically reducing operating costs is to curate a large input-output dataset obtained from running queries against large, SOTA models, and then using it to fine-tune a small model to be highly specialized for a singular purpose. The minified, fine-tuned model can then be run locally on a GPU cluster for a fraction of the cost compared to running generalized SOTA models at scale.
Testing for Vulnerabilities
While using LLMs as a service in the initial stages, your security posture is fortified by substantial investments from companies like Microsoft, OpenAI, Google, or Anthropic in red-teaming and vulnerability assessments. Credible open-source models like LLaMa2/LLaMa3 or Mistral are subjected to rigorous testing, but updates on emerging threats may not parallel those of premium LLM services. When deploying LLMs internally, you shoulder the responsibility of implementing safeguards against newly discovered exploits and batch processing serves as a critical tool for vulnerability scans against unethical and harmful prompts.
Monitoring
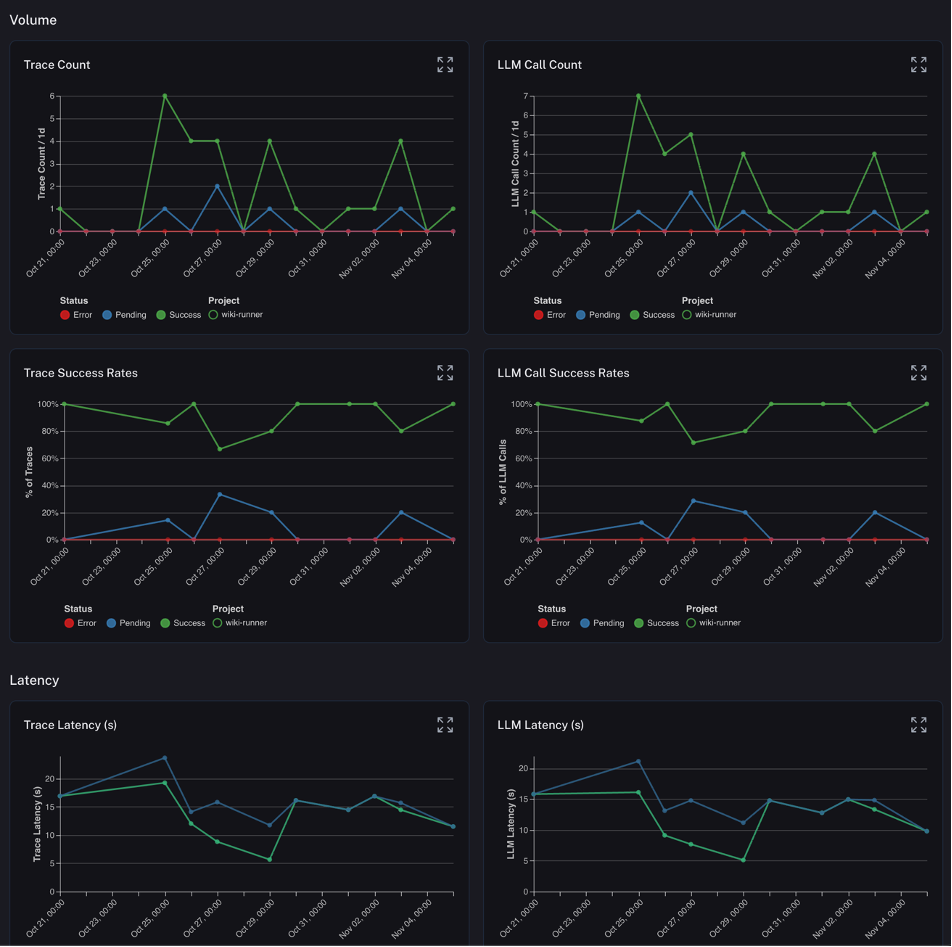
LangSmith's capabilities extend to real-time monitoring as well, providing visibility into the performance and behavior of our AI applications. This observability is instrumental in maintaining operational integrity and responding to issues with agility.
Conclusion
By making reliability and rigorous testing a priority, we enable LLMs to fulfill their tremendous potential. Tracing model behavior, integrating user feedback, curating datasets, scanning for vulnerabilities, and monitoring systems builds essential trust in AI applications. As pioneers in this space, we have an obligation to develop LLMs responsibly and set the bar high. The frameworks outlined here pave the way for LLMs that transform industries while prioritizing safety and ethics. With care and diligence, we can usher in an era of trustworthy AI that humanity can rely on.