- Published on
Build Automated Test Suites with Playwright
- Authors

- Name
- Dan Orlando
- https://x.com/DanOrlando15
End-to-end testing is an important step in the software development process, as it helps to ensure that the application works correctly from start to finish, including all user interactions and system integrations. Test automation is a critical element for web application scalability. In this blog post, we will explore how you can use Playwright to perform end-to-end testing for your web applications using real-world examples from an enterprise grade web application.
What is Playwright?
Playwright is a Node.js library that allows developers to automate their end-to-end testing for web applications. It provides a simple and intuitive API for testing user interactions, such as clicking buttons and filling out forms. Playwright supports three popular web browsers: Chromium, Firefox, and WebKit, which means that you can test your application in multiple browsers with just one tool.
Why use Playwright for end-to-end testing?
One of the main benefits of using Playwright for end-to-end testing is its ability to automate the entire testing process. This means that you can test your application quickly and efficiently, without having to manually perform each test step. Another benefit of Playwright is its ability to interact with the DOM. This means that you can test not just the user interface, but also the underlying code that makes up the page. This is particularly useful when testing dynamic or interactive web pages.
Getting started with Playwright
The Playwright documentation provides information on getting setup and configured in your repository if you haven't already done so. In this article I will focus on important concepts and best practices for building Playwright tests, along with tips and techniques for working effectively with the platform.
Playwright provides a simple API for writing tests. The API is similar to the one used by Selenium, but with a few important differences. For example, Playwright uses the page object to interact with the DOM, whereas Selenium uses the driver object. Playwright also provides a browser object, which allows you to interact with the browser itself, such as opening new tabs and windows.
Navigation
There are three ways to navigate to a page in Playwright. The most common way is to use the goto method, which takes a URL as an argument as seen in the example above. You can also use DOM interaction, typically in the form of the click method to click a link, which will navigate to the page that the link points to. Finally, you can use the back and forward methods to navigate to the previous and next pages in the browser history.
We generally want to simulate the way in which a user will interact with the site by clicking links and buttons, but often you'll want to just navigate directly to a specific page. Let's say you're testing all of the features on the product page of an ecommerce site. Having to render multiple pages to get to where you want to be is expensive if you have a lot of tests, so the best approach is to have a separate test that runs through all of the navigation, and when it comes to testing the product page, use the goto function to go directly to the page rather than loading the homepage and clicking through things to get to the product you're looking for in every test.
await page.goto('/register');
In fact, it is a good idea to keep the Single Responsibility Principle in mind when writing tests. Each test should generally have a single purpose, and should not be concerned with other aspects of the application. In our ecommerce example, if we're testing the "add to cart" button on the product page, we should not be concerned with the navigation to the product page. We should have a separate test that verifies that the navigation works correctly.
This does not mean you shouldn't have multiple assertions in the same test however. This brings up an important concept to understand about Playwright - tests run in isolation. This means that for every test, Playwright loads an entirely new instance of Chromium. You can significantly reduce the amount of time it takes to run through the test suites by combining multiple assertions into a single test where possible. This is more efficient than loading a new browser and then rendering the page multiple times for each assertion.
DOM Interaction with Locators
Locators are used to find elements on a page. Locators come with auto waiting and retry-ability. Auto waiting means that Playwright performs actionability checks on the element in question, such as ensuring the element is visible and enabled before it performs the click. Playwright supports a variety of locators, including CSS selectors, XPath, text. For example, XPath attributes like id and data-testid, as well as tag names can be used to locate elements. Consider the following example:
test('Filling out the lookup form and show user not found error', async ({page}) => {
await page.goto('/register');
await page.locator('h1:has-text("First, let\'s find your account")').waitFor();
await page.fill('#lastName', 'UserDanTestAccountA');
await page.fill('#dateOfBirth', '01/01/2001');
await page.fill('#employeeId', 'unknown user');
await page.click('button:text("Find Account")');
await expect(page.locator('[data-testid="regError"]')).toHaveText(
'The information provided did not match our records. Try again or click the help link for more information about finding your account.'
);
});
This test is an account pre-registration form that allows users to find their account by entering their last name, date of birth, and employee ID, at which point the registration form loads if the account is found. If the user is not found (the use case for this test), an error message should be displayed. The test starts by navigating to the page, then filling out the form and clicking the "Find Account" button. It then waits for the error message to appear, and finally verifies that the error message is correct.
You can see that we're using a variety of locators in this test. Before we do anything, we want to make sure that the form is ready for interaction by using the Locator.waitFor function to check that the page is loaded by waiting for the h1 element with the text "First, let's find your account" using the :has-text pseudo-selector, which allows us to locate an element by its text content. We then interact with each element based on it's id selector. The button element is located using the :text pseudo-selector. The data-testid attribute is used to locate the error message element, where we check to see if it has the correct error text.
While this test works, there is a problem with this approach in that it doesn't exactly follow best practices. The problem is that these locators are not resilient to changes in the DOM. If the id were to change, or if we were selecting by classname and the designer were to change the name of a class, the test will break. Additionally, the id attribute should be unique, but it is not guaranteed to be unique. The page that this test runs on has multiple forms (account lookup and registration). If the elements were given the same ID's, perhaps because the components housing the forms were written by different developers, it would be possible for the test to fail because the wrong form was filled out. Lastly, littering your code with data-testid attributes is not a good practice and can be a pain to keep track of. That said, we should generally prefer user-facing attributes to XPath or CSS selectors. Consider this revised example:
test('Filling out the lookup form and show user not found error', async ({page}) => {
await page.goto('/register');
await page.locator('h1:has-text("First, let\'s find your account")').waitFor();
await page.getByRole('textbox', { name: 'Last name'}).fill('UserDanTestAccountA');
await page.getByRole('textbox', { name: 'Date of birth' }).fill('01/01/2001');
await page.getByRole('textbox', { name: 'Unique ID' }).fill('unknown user');
await page.getByRole('button').filter({ hasText: "Find Account" }).click();
await expect(page.getByRole('alert')).toHaveText(
'The information provided did not match our records. Try again or click the help link for more information about finding your account.'
);
});
This revised example uses the getByRole function to locate the elements. The getByRole function is a Playwright helper function that uses the ARIA roles to locate elements. The getByRole function is a great way to locate elements because it is resilient to changes in the DOM. Additionally, you get the added benefit of testing the accessibility of your application with this approach. We should want our tests to fail if the elements on the page do not have the correct ARIA roles.
The getByRole function also allows you to locate elements by their text content, which is a great way to locate elements without having to use data-testid attributes. Also notice that we're using the filter function to filter the button by its text content. Locators can be chained in this way to narrow the search. Say, for example, that you had a combobox for t-shirt sizes where each option in the combobox had the t-shirt size text with a small button next to it for adding the option to the shopping cart. You could use locator chaining to find the button for the large t-shirt and add it to cart like so:
await page.getByRole('listitem')
.filter({ hasText: "Large" })
.getByRole('button', { name: 'Add to cart' })
.click();
Note:
namepertains to thearia-labelattribute of an HTML element, andhasTextis a Playwright-specific pseudo-selector that allows you to locate an element by its text content.
Assertions
Playwright uses the jest-expect library for assertions. This includes assertions like toBeVisible, toHaveValue, toHaveText, and toHaveClass.
These assertions are used to verify that the page is in the correct state after an action has been performed. Negative matchers can also be used to test that the opposite is true by adding .not in front of the matcher. For example, using our account lookup form, we can verify that the error message is not present after the form has been filled out correctly:
test('Filling out the lookup form with lookup success and showing the register form', async ({
page,
}) => {
await page.goto('/register');
await page.locator('h1:has-text("First, let\'s find your account")').waitFor();
await page.getByRole('textbox', { name: 'Last name'}).fill('UserDanTestAccountA');
await page.getByRole('textbox', { name: 'Date of birth' }).fill('01/01/2001');
await page.getByRole('textbox', { name: 'Unique ID' }).fill('TestUserDanTestAccountA');
await page.getByRole('button').filter({ hasText: "Find Account" }).click();
await page.locator('h1:has-text("Register Account")').waitFor();
await expect(page.getByRole('form', { name: 'Registration Form' })).toBeVisible(); // register form is visible
await expect(page.getByRole('alert')).not.toBeVisible(); // error message is not visible
});
Note that the waitFor function is again used here to tell Playwright to pause after the lookup form is submitted and wait for the registration form to appear before continuing.
Using the Test Generator
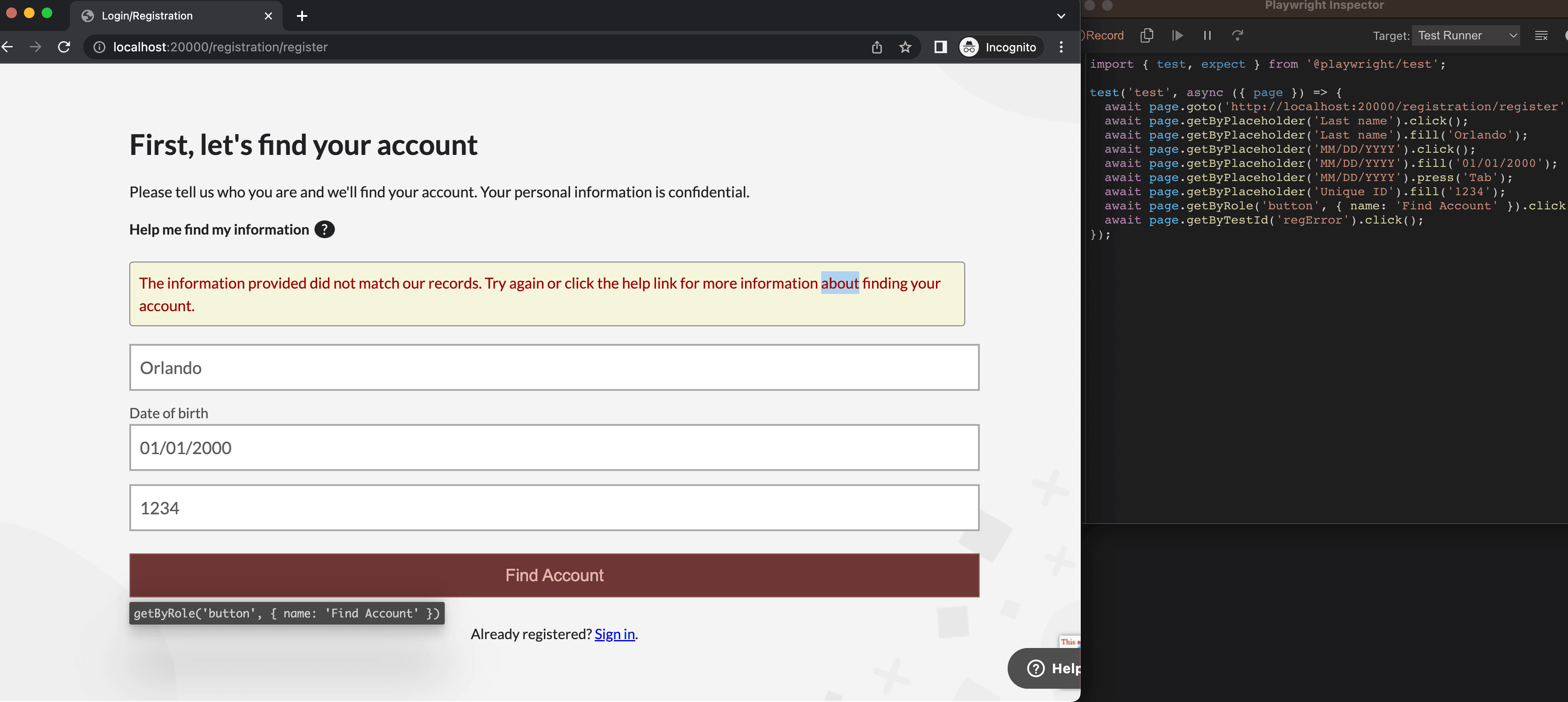
Playwright provides a test generator that can be used to generate the test code for the interactivity with a web application. This can be run from the command line using the npx playwright codegen <url> command, where url is the page you want to test (eg. http://localhost:20001/registration/register). The test generator will open a browser window and allow you to interact with the application.
As you interact with the application, the test generator will record the actions and generate the test code for them. I have mixed feelings about the test generator however, as it doesn't always generate the code the way I want. For example, I generally prefer the getByRole as it has the dual function of testing the accessibility of the element, but it seems the test generator prefers getByPlaceholderText for filling out a form. Additionally, if it sees a data-testid on an element, it will use that instead of getting the element by role, as you can see from the generated code below:
test('test', async ({ page }) => {
await page.goto('http://localhost:20000/registration/register');
await page.getByPlaceholder('Last name').click();
await page.getByPlaceholder('Last name').fill('Orlando');
await page.getByPlaceholder('MM/DD/YYYY').click();
await page.getByPlaceholder('MM/DD/YYYY').fill('01/01/2000');
await page.getByPlaceholder('MM/DD/YYYY').press('Tab');
await page.getByPlaceholder('Unique ID').fill('1234');
await page.getByRole('button', { name: 'Find Account' }).click();
await page.getByTestId('regError').click();
});
Mocking API Requests
API mocking is a powerful tool that can be used to improve the reliability of tests. However, before we get into how API requests are mocked, it is important to understand when and when not to mock API requests. Consider the following guideline when determining whether or not to mock an API:
External Dependencies
API mocking should be used to mock out external dependencies that are not under your control. For example, if you are testing a web application that uses a third-party API to retrieve data, you should mock the API request to ensure that your test is not dependent on the availability of the third-party API.
Internal Dependencies
The answer to whether or not an internal dependency (ie. a backend service that is internal to the application) is - it depends. Internal API requests should be mocked when they are not relevant to the test. As I said earlier, Playwright tests run in isolation. This means that the application is reloading for every test. In the user-facing application that we work with at Limeade, we have a number of API requests that are made for each page load, including loading startup data, user profile, checking for consents, notifications, feature enablement, programs, cards, categories, and so on. If I'm testing a feature like making a post to the social feed, I don't care about any of that data. I only care about the data that is relevant to the feature that I'm testing.
In this case, I would mock the irrelevant API requests to ensure that the test is not dependent on the availability of those APIs. I would not mock the request for the social feed (ie. posting to the feed and then testing that the post is visible). This way, if the test fails, I can immediately look at what I'm getting back from the API request and see if the data is in the correct state without wondering if the problem is related to some other service.
Does this mean that the mock data has to always be the same as the actual data, requiring someone to always have to be keeping the mocks in sync with the database model? The answer to this question in most cases is simply - No. Consider the mocked APIs as a way to get past the requirements of the application so you can get to the actual feature that you're testing. The mocks do have to meet those requirements however.
For example, if a new property is added to the user profile model, and the application now requires that property to run, then the API mock for that request will need to be updated to include that property. Its still a good idea to try and keep the mock data model consistent with the actual model, but its not something to stress over as long as the application runs and you can test the features that you need to.
How to Mock an API Request
Playwright provides a simple API for mocking API requests. The API is based on the Fetch API and is available on the page object. The page.route method is used to intercept requests and provide a mock response. The page.route method takes a URL pattern and a callback function. The callback function is called with the route object that can be used to provide a mock response. The route object has a fulfill method that can be used to provide a mock response. The fulfill method takes an object with a status and body property. The status property is the HTTP status code that will be returned, and the body property is the response body that will be returned.
Each mock should kept in a separate file contained in a /mocks directory to keep the test files clean. The following example shows the mock API request for a user profile endpoint:
export const mockUserProfile = {
status: 200,
headers: {
'Access-Control-Allow-Origin': 'http://localhost:3001',
},
contentType: 'application/json',
body: JSON.stringify({
AboutMe: null,
Anniversary: null,
Banner: 'https://domain.com/api/v2/profile/banner/879291/8d9ec73ef4d3e95',
Birthday: null,
ContactEmail: null,
Department: null,
DisplayName: 'MFETestAutomationPA',
Email: 'TestAutomation@outlook.com',
EnableChat: false,
Expertise: null,
FirstName: 'MFETest',
Image: 'https://domain.com/api/v2/profile/image/879291/8d9ec73ef4d3e95',
IsPersona: false,
LastName: 'AutomationPA',
Location: null,
ModifiedDate: '2022-02-10T00:00:00',
UserId: 879624,
Phone: null,
Revision: '8d9ec73ef4d3e95',
Skills: null,
Title: null,
UPN: null,
}),
};
Notice how we're passing http://localhost:3001 to the Access-Control-Allow-Origin. This is done to ensure that the request does not result in a CORS error. Additionally, we must use JSON.stringify() to simulate the actual body of the API request. It is also worth noting that we can simply passing null for a lot of the properties of the user info object. This is because the application doesn't actually need those properties to run.
To use this mock, we first import it into the spec:
import {mockUserProfile} from '../__mocks__/mockUserProfile';
Then, assuming that the features being tested are unrelated to the user profile, we can simply tell Playwright to use this mock for the user profile API request for every test in the spec:
test.beforeEach(async ({page}) => {
page.route('**/api/users/profile/879624', (route) => route.fulfill(mockUserProfile));
});
Snapshot Testing
As with mocking API requests, it is important to know the distinction between when a snapshot test is appropriate and when it is not. Snapshot tests are useful for testing the visual appearance of the page, and are therefore ideal when regressions in the display of the application is a concern. For example, you might want to have a single snapshot test on first load of a page to ensure that any changes to the visual appearance is intentional.
There are some important things to consider when determining whether or not to use a snapshot test. First, snapshots are difficult to maintain when there are a lot of them, and should therfore be used sparingly. Second, snapshot testing is expensive as every pixel of the newly taken snapshot is compared to the previous snapshot.
In the example of posting to the social feed, consider testing that the new post is added to the feed by checking that the post is in the DOM. This is a much more efficient test than taking a snapshot of the entire page.
I will also say from experience that debugging failed snapshots can actually be surprisingly difficult. We'll get into that in Part 2, where we look at debugging Playwright tests.
How to Take a Snapshot
To take a snapshot, use the Page.screenShot method. Then do the snapshot comparison with toMatchSnapshot, passing it the name of the file that the snapshot will be saved to.
test('Loads landing page', async ({page}) => {
await page.goto('/register');
await page.locator('h1:has-text("First, let\'s find your account")').waitFor();
const screenshot = await page.screenshot();
expect(screenshot).toMatchSnapshot('landing.png');
});
You can then generate the initial snapshot by running the following command:
playwright test --config=<your config file> --update-snapshots
Conclusion
Playwright is a powerful tool for automating end-to-end testing of web applications. Playwright is a no-brainer when considering its eaee-of-use compared with tools like Selenium that have been around for a while and features like support for multiple browsers and devices.
In this article, we looked at how to use Playwright to write end-to-end tests for a React application. We looked at how to create tests using Playwright locators and assertions, how to use Playwright to mock API requests and take snapshots, and discussed considerations to be made regarding best practices. In the next article, we'll look at improving test reliability and methods for debugging Playwright tests.