- Published on
Profitable AI: How to Minimize LLM Inference Expenses and Boost Scalability
- Authors

- Name
- Dan Orlando
- https://x.com/DanOrlando15
I have spent the last year building a scalable enterprise AI platform for a large private company and a significant portion of this effort has centered around how to reduce the cost of running LLM inference. This article describes in detail several techniques that I've learned for maximizing profitability and minimizing waste.
Table of Contents
- LLM Product Maturation Lifecycle
- Strategies for Reducing LLM Inference Costs
- LLM Routing
- LLMLingua
- Conversational Memory Optimization and Caching
- Fine-tuning
- Solution Demonstration
- LLM Hierarchy
- Conclusion
LLM Product Maturation Lifecycle
Large language models (LLMs) have opened up exciting new frontiers in artificial intelligence, allowing interactive conversational interfaces, content generation, task automation, and more. However, running inference using third-party APIs at scale is not economically feasible. The chart below shows the cost of deploying an LLM application to production in the y-axis, with respect to model endpoints, model training, and engineer salaries.
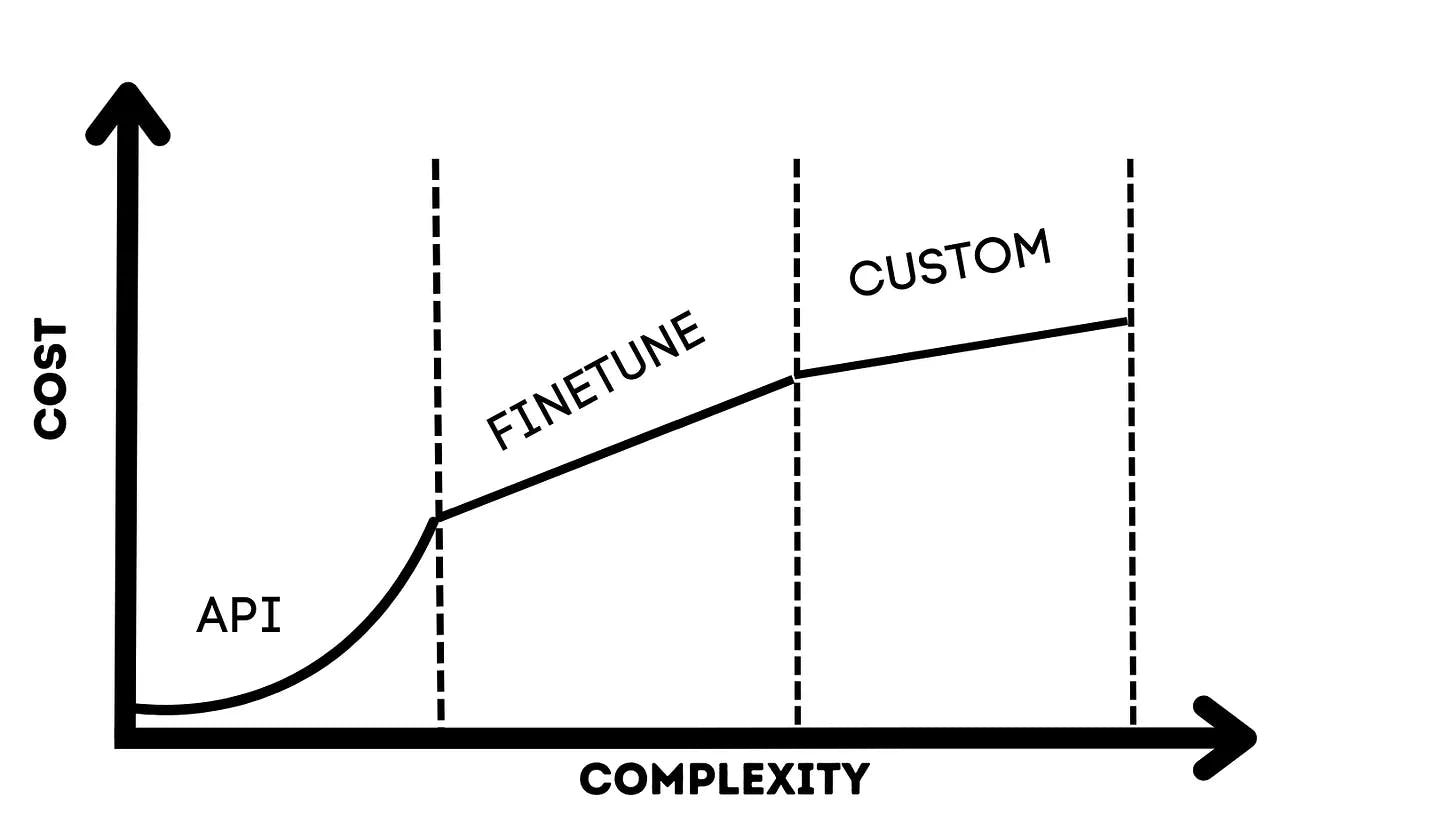
The narrative of the plot unfolds in three segments: API, finetune, and custom. These segments represent the evolutionary stages of a machine learning product throughout its development journey, from inception to maturity. This progression is typical for any ML product, whether it's the initial offering of a startup or a fresh application within a large tech company.1
As companies aim to monetize LLM-powered applications, minimizing inference costs is essential for profitability, which is why its crucial that effective techniques for cost management are implemented early in the development stages of the product. While LLM capabilities continue advancing rapidly, if left unchecked these expenses could make many applications financially unviable as soon as the product begins to scale.
Most companies will start by building proof-of-concept applications against third-party APIs, which is the most expensive way to run LLM inference but allows them to get products to market quickly. The chart shows that the cost of using these APIs at scale is exponential. The value of implementing the techniques I will describe here is in limiting the extent of this exponential curve.
As the product matures, the company will likely move to self-hosting one or more LLMs for specific tasks. Finally, as the product becomes more established, the company will likely invest in custom LLMs. In these latter stages, the value of these techniques primarily lies in slowing the linear growth of things like infrastructural resources required to support the LLMs themselves by increasing the efficicieny of the applications.
Strategies for Reducing LLM Inference Costs
Through my research, experimentation, and devlopment, I have found the following strategies to have a dramatic impact on LLM inference cost reduction:
LLM Routing: Rather than using a single LLM, queries are dynamically routed to the most efficient model for the task at hand. Combining multiple LLMs in this way increases performance while reducing costs up to 60%.
LLMLingua: This method optimizes language processing to dramatically reduce tokens and associated computational costs. LLMLingua uses a compact language model to identify and remove non-essential tokens from prompts, enabling up to 20x compression when querying large LLMs.
Memory Optimization: Enhancing how LLMs cache and retrieve information prevents redundant calculations over the same data, significantly reducing computational workloads.
Fine-tuning: By optimizing general-purpose LLMs for specific tasks through fine-tuning, costs can be reduced by 50% or more.
Solution Demonstration and LLM Hierarchy: Specializing multiple agents to work together enhances efficiency. Successful query resolutions are captured and used to accelerate future responses, reducing redundant computation.
While many factors influence overall application costs, aggressive optimization of LLM inference is essential for enabling profitable, scalable products and services. Emerging techniques make major headway on this challenge, with methods like cascading, compression, routing, and prompt optimization slashing costs by orders of magnitude. As these innovations advance, LLM applications will become ever more compelling and viable.
LLM Routing
The concept of LLM Routing was first introduced in the paper "HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face", and describes a dynamic strategy that significantly enhances the cost-effectiveness of using Large Language Models by directing queries to the most suitable model based on the specific task at hand. This approach ensures that each query is handled by the model that offers the best balance between performance and computational cost.
How It Works
LLM Routing involves maintaining a "mixture of experts" pool of models with varying capacities and specialties. It operates in four stages: Task Planning, Model Selection, Task Execution, and Response Generation. When a query is received, an initial assessment determines the complexity and requirements of the task. Based on this assessment, the query is routed to the model that is best suited to handle it efficiently. This could mean directing simple queries to smaller, less resource-intensive models and more complex queries to larger, more capable models.
LLM as Controller
The LLM controller manages and organizes the cooperation of expert models. The LLM first plans a list of tasks based on the user request and then assigns expert models to each task. After the experts execute the tasks, the LLM collects the results and responds to the user.
Workflow
The workflow, which includes LLM routing, consists of four stages:
- Task Planning: The LLM analyzes the requests of users to understand their intention and disassemble them into possible solvable tasks.
- Model Selection: To solve the planned tasks, the LLM selects expert models based on model descriptions.
- Task Execution: The LLM invokes and executes each selected model and returns the results to itself.
- Response Generation: Finally, the LLM integrates the predictions from all models and generates responses for users.
Benefits of LLM Routing
Cost Efficiency: By dynamically selecting the most appropriate model for each task, LLM Routing can reduce unnecessary computational expenses, achieving as much as a 60% reduction in costs without compromising quality.
Improved Performance: This strategy not only saves costs but also can lead to faster response times and increased accuracy, as queries are matched with models optimized for those specific types of tasks.
Adaptability: LLM Routing is highly adaptable, allowing for the integration of new models into the routing pool as they become available, ensuring that the system remains at the cutting edge of efficiency and effectiveness.
LLMLingua
LLMLingua introduces a novel approach to optimizing language processing tasks, significantly reducing the computational demands of LLM inference. At the heart of LLMLingua is the utilization of compact, well-trained language models (e.g., GPT-2-small, LLaMA-7B) to preprocess prompts. This preprocessing involves identifying and removing non-essential tokens, effectively streamlining the input for larger models.
The framework compresses the prompt to increase key information density, reduce information loss in the middle, achieve adaptive granular control during compression, and improve the integrity of key information. Experiments show that LLMLingua can enhance LLMs' performance while reducing costs and latency.
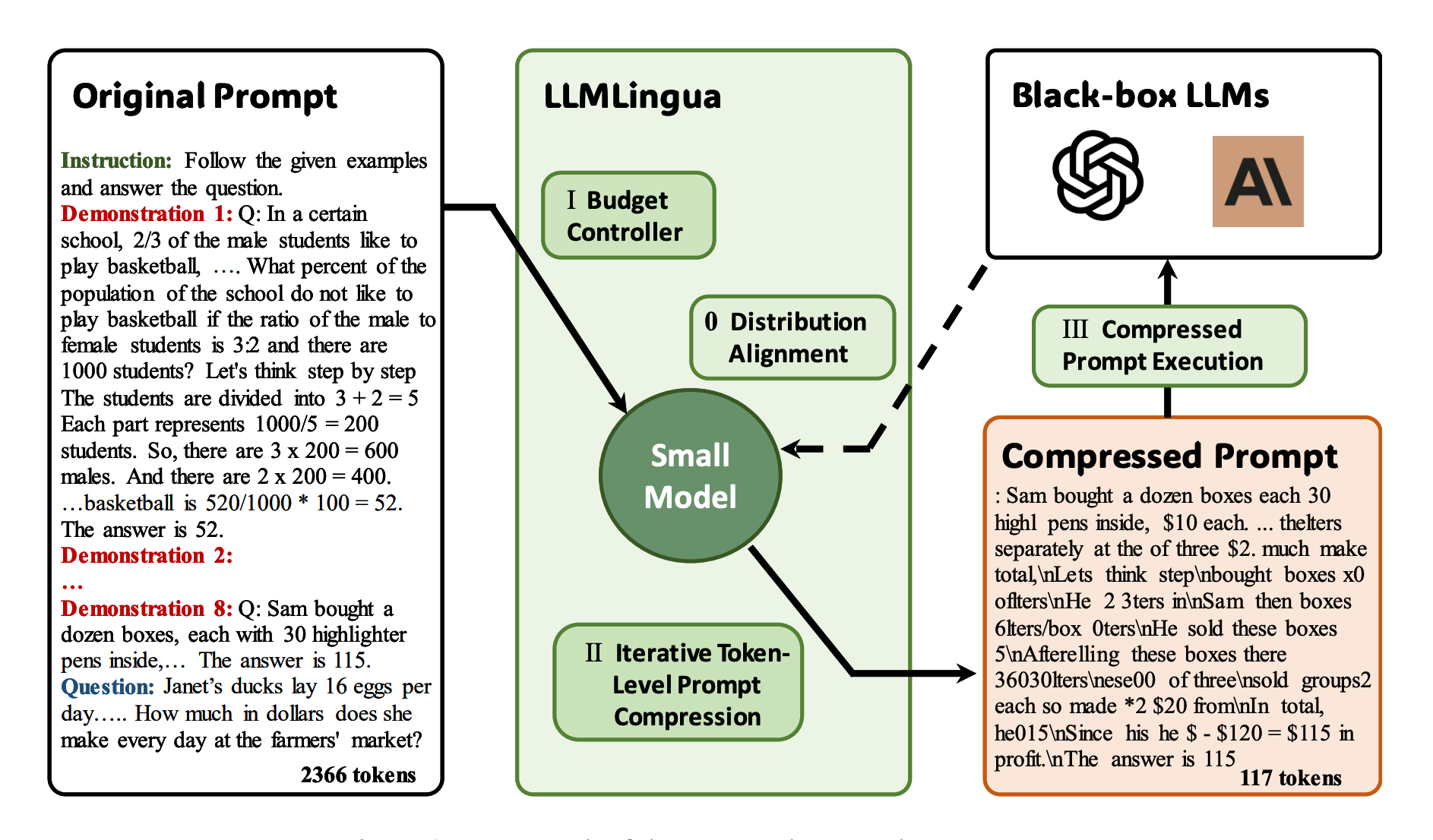
By minimizing the computational load required for each task, LLMLingua enables more efficient operation of LLMs. This optimization is especially valuable for services that rely on rapid processing of natural language inputs, such as automated translation services, content generation tools, and interactive chatbots. The project is based on two papers published by Microsoft Research titled "LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression" and "LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models".
The LLMLingua paper describes a series of experiments showing that this prompt compression approach achieves state-of-the-art performance on four datasets (GSM8K, BBH, ShareGPT, and Arxiv-March23) with up to 20x compression and minimal performance loss. Specifically, on GSM8K and BBH, their method slightly outperforms the full-shot approach while maintaining impressive compression ratios. On ShareGPT and Arxiv-March23, it achieves acceleration ratios of 9x and 3.3x with high BERTScore F1, indicating effective retention of semantic information.
For applications that rely on APIs for inference, cost savings come in the form of the number of input tokens being greatly reduced. For self-hosted models, queries are less resource-intensive, allowing for more simultaneous requests to be processed with less hardware. In both cases, the subsequent inference is much faster because the model has fewer tokens to process.
Conversational Memory Optimization and Caching
The ability to reference previously disclosed information is vital for conversation. At the very least, a conversational system requires access to a history of recent messages. A more sophisticated system necessitates an ever-updating world model that tracks entities and their associations. This allows the system to maintain context about referenced people, places, and things.
Storing chat messages is quite simple. However, creating data structures and algorithms that provide the most useful view of those messages is more complex. A very basic memory system may just show the most recent messages with each session. A slightly more advanced system could summarize the last K messages. An even more intelligent system might analyze entities mentioned in saved messages and only display information about entities brought up in the current session.
Summarization
Conversational memory can be compressed by summarizing the history after K turns. There are multiple derivations of this technique. For example, LangChain's memory implementation includes a Conversation Summary Buffer where the most recent interactions are kept but older messages are summarized after a certain number of turns to limit the input tokens sent in the chat history.
Semantic Memory Retrieval
This technique involves storing and indexing past messages in a vector database for efficient retrieval of only relevant messages to the query. In LangChain, the VectorStoreRetrieverMemory saves memories in a vector database and searches for the K most relevant records whenever accessed.
Unlike most other Memory classes, it does not explicitly log the sequence of interactions. In this system, the vector store "docs" represent prior conversation extracts. This allows the AI to refer back to useful information it was provided earlier in the dialogue. The vector similarity matching identifies the most pertinent passages to the current context.
The vector store retriever memory technique provides more than just cost savings benefits - it also enables more robust long-term memory capabilities. By storing conversation snippets in an unordered vector database rather than a sequential log, this method removes constraints on memory capacity over time. The AI system can scale to accumulate vast stores of conversational history to reference, and the vector similarity matching allows for efficient lookup of relevant passages without needing to search through an ever-growing sequential record. This makes the maintenance of long-term memory feasible, as old interactions can still be surfaced if vectorally relevant without storage or processing bottlenecks. In other words, the unordered and efficient vector indexing approach not only saves infrastructure resources but more importantly enables practically unlimited memory of previous interactions. This facilitates richer and more contextual dialogues over long time periods.
Through my development of various prototypes, I've grown quite fond of the Zep memory server implementation, which summarizes, embeds, and enriches chat histories asynchronously. I would definitely recommend reading about Zep's Perpetual Memory. It's a great example of a system that can be used to implement the techniques described here.
Caching Common Queries
I would be remiss if I didn't say something about caching. As you may have guessed, the idea here is to cache LLM responses to frequent first-turn queries and serve those cached results instead of generating new text for common questions.
For example, questions like "What is my copay for a primary care doctor visit?" will likely have consistent responses across different users. By caching these duplicate LLM outputs, the application can save on token generation costs and accelerate response times for a better user experience.
It's important to note this caching only works on the first conversational turn with an LLM before any context has been established. After the first response, users will supply unique follow-up questions and remarks that include chat history and personalized context. These subsequent requests must call the LLM for customized responses. Nevertheless, applications relying on LLMs for conversation can realize significant efficiency gains by caching initial small talk queries before unique dialogue contexts emerge.
Fine-tuning
Fine-tuning involves adjusting the model's weights based on a smaller, task-specific dataset, which can lead to a more efficient use of computational resources. By optimizing a pre-trained LLM for a specific task, it's possible to achieve substantial cost reductions with relatively little effort. This enables significant improvements in model performance and efficiency.
Implementing fine-tuning can reduce computational demands by up to 35% with just an afternoon's work. This efficiency gain comes from the model's improved ability to quickly home in on relevant responses, thereby using less processing power. Moreover, further optimizations, such as pruning less important weights or adjusting model layers specific to the task, can (at a minimum) halve the costs associated with LLM inference.
A particularly effective method within this strategy involves using a dataset of user interactions with a large, state-of-the-art model to fine-tune a smaller model. This process harnesses the rich, nuanced data derived from real-world use cases to create a more targeted and efficient model.
Leveraging User Interaction Data
Real-World Learning: By collecting and analyzing interactions between users and a large LLM, developers can identify common queries, challenges, and successful response patterns. This dataset becomes a goldmine for training smaller models, as it contains practical examples that reflect actual user needs and language nuances.
Customization and Efficiency: Fine-tuning a smaller model with this dataset tailors the model to handle real-life interactions more effectively. This customization reduces the need for the model to process and learn from the entire scope of possible language interactions, focusing instead on those most relevant to its intended application. Consequently, this leads to a leaner, faster, and more cost-efficient model.
Enhanced Performance with Reduced Size: Despite their smaller size, models fine-tuned on specific interaction datasets can outperform larger models in targeted tasks. This is because the fine-tuning process imbues them with a concentrated understanding of the specific domain or type of interaction they're optimized for, making them highly effective within their niche.
Practical Example
Imagine a customer support scenario where a small model is fine-tuned using a dataset of customer interactions with a company's previous, larger LLM-based support system. This smaller model, now specialized in the company's specific support queries and language, can handle most customer interactions with a fraction of the computational resources required by the larger model. Such an approach not only drastically reduces operational costs but also maintains, if not enhances, the quality of customer support.
Strategic Benefits
This fine-tuning approach offers several strategic benefits:
Cost-Effectiveness: By optimizing a smaller model for specific interactions, organizations can achieve as much as 98% cost savings by eliminating reliance on APIs and significantly reducing the computational requirements of LLM inference.
Tailored Solutions: Models become highly specialized in addressing the needs and language of their specific user base, improving overall user satisfaction.
Scalability: This method allows for the efficient scaling of AI solutions, as smaller, fine-tuned models can be deployed across various platforms and devices with limited computational capabilities.
The Cost Advantage of Fine-tuning Over RAG
Fine-tuning is a highly effective method for reducing inference costs, not only by optimizing the model's performance but also by minimizing the need for extensive prompts. This strategy becomes particularly compelling when compared to Retrieval-Augmented Generation (RAG) approaches, which, while powerful, rely on dynamically pulling in external data during the inference process.
Data Integration: Fine-tuning integrates essential data and knowledge directly into the model's parameters. This contrasts with RAG, which retrieves information from external sources in real-time to augment its responses. While RAG can provide highly relevant and up-to-date information, the process requires querying large databases, which can increase computational load and inference time.
Prompt Efficiency: A significant advantage of fine-tuning is its impact on prompt sizes. Because the model is tailored to understand and generate responses based on its training, including task-specific nuances, there's less need to provide extensive background information in each prompt, resulting in less input tokens being sent to the model. This efficiency is in stark contrast to RAG, where prompts may need to include more context to guide the model's retrieval process effectively. Furthermore, if these context tokens are being passed back and forth with each interaction as part of the conversation's chat history, the cost of a single conversation can be significantly higher.
Computational Benefits: By reducing the reliance on external data retrieval and minimizing prompt sizes, fine-tuning offers a more computationally efficient route. This direct approach ensures that the model operates with a higher degree of self-sufficiency during inference, leading to faster response times and lower resource consumption.
Practical Implications
In practice, fine-tuning allows for a more streamlined interaction with LLMs. Again using our customer service example, a fine-tuned model can directly apply its integrated knowledge to resolve queries without the overhead of fetching additional information. This results in a double benefit: reduced computational costs and a more fluid, responsive user experience.
Comparatively, while RAG offers the advantage of leveraging extensive, dynamically accessed databases, it does so at the expense of increased computational demands. Therefore, for applications where prompt length and computational efficiency are critical, fine-tuning presents a compelling advantage by embedding necessary knowledge within the model itself.
The choice between fine-tuning and RAG ultimately depends on the specific requirements of an application. Fine-tuning is ideal for tasks with well-defined boundaries and a static knowledge base, where reducing prompt sizes and computational overhead is paramount. Conversely, RAG shines in scenarios where accessing the latest information or covering a broad knowledge domain is essential, despite the larger computational footprint.
Solution Demonstration
For advanced systems with multiple cooperating agents and tools, demonstrating prior successful solutions can greatly improve performance and reduce computations. This technique involves logging fully resolved queries and responses to a vector database and reusing them to accelerate future related inquiries.
When a query is conclusively addressed as resolved from human feedback, the system stores the query-resolution pair in a vector database. Upon receiving new queries, it identifies the most similar past query from this database, and appends the associated solution to the prompt - serving as a demonstration for resolving the new case.
By reusing previous query-solution pairs in this way, the system requires fewer iterations to address new queries and improves its overall efficiency. Solutions built on this concept include Microsoft's AutoGen EcoAssistant which combines demonstration solutions with an assistant hierarchy for code execution.
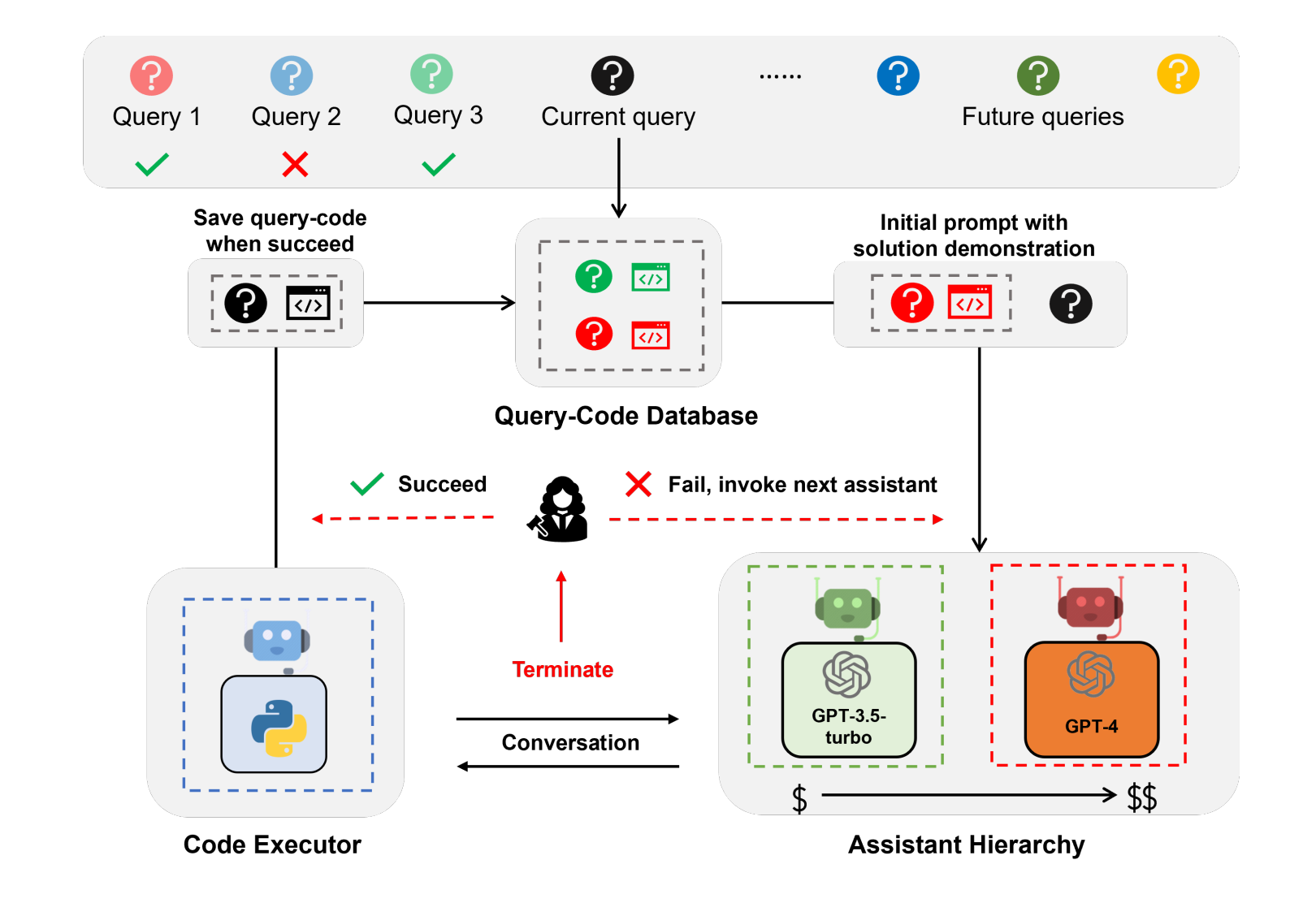
LLM Hierarchy
The concept of an LLM hierarchy uses cheaper language models first, only escalating to more expensive models as necessary. EcoAssistant starts conversations with the most affordable model. If unable to resolve the query, it increments to better models until resolution - drastically cutting costs. In their experiments with Places, Weather, and Stocks datasets, EcoAssistant was able to achieve a higher success rate with an average 75% cost reduction compared to a single GPT-4 model.
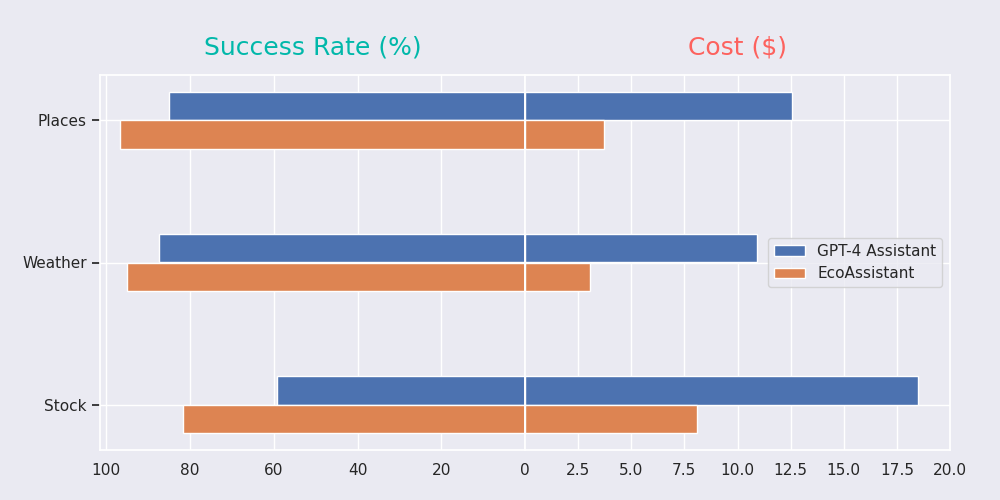
On top of this, supplementing prompts with solved use cases from the vector database further reduces iterations required at each layer of the hierarchy2. Driving this efficiency is the high reuse rate of prior solutions. By simply appending the historical solutions to prompt new models, the computation required is slashed. And solution demonstration scales very well as the database expands over time. With more resolved use cases populated, the technique has more potential matches to leverage. So cost savings generally compound going forward rather than hit a ceiling. Building up this query history does require some ramp-up time investment before seeing major returns however.
Overall, while solution demonstration provides first-line computational savings, supplementing with the LLM hierarchy takes the efficiency to entirely new levels. The synergistic effects between method reuse and selective model escalation underpin the transformative cost reductions exhibited by these techniques.
The mental model that I have used to explain the difference between LLM Hierarchy and LLM Routing is that the hierarchy is a sort of chain that starts with the smallest, most efficient model and works its way up to the largest, most capable model. LLM Routing, on the other hand, starts with a small agentic model that acts as the controller to a pool of models of varying sizes that can be fine-tuned experts or general purpose.
Conclusion
the journey to reduce LLM inference costs while maintaining, or even enhancing, the performance of enterprise AI applications requires a multi-faceted approach, as detailed through the exploration of various innovative strategies in this article. From leveraging LLM routing for dynamic model selection to employing fine-tuning techniques for task-specific optimizations, each strategy presents a unique opportunity to significantly lower operational expenses. The introduction of methods like LLMLingua for prompt compression and the strategic use of memory optimization and caching further exemplifies the potential for cost-efficient LLM deployment.
Moreover, the practical implementations of these strategies, such as the integration of solution demonstration and LLM hierarchy, underscore the tangible benefits of adopting a layered approach to AI application development. These techniques not only demonstrate substantial cost savings but also improve the responsiveness and accuracy of AI services, making the promise of scalable, economically viable LLM-powered applications a reality.
As AI technology continues to evolve, the importance of cost management in ensuring the sustainability and scalability of LLM applications cannot be overstated. The strategies discussed here offer a blueprint for developers and organizations to navigate the complexities of LLM inference costs effectively. By embracing these innovations, the AI community can look forward to developing applications that are not only technologically advanced but also financially accessible, paving the way for a future where AI's potential can be fully realized across industries.
Footnotes
Soham, C. (2023, Apr 6). The Economics of Building ML Products in the LLM Era. ScaleDown. https://tinyml.substack.com/p/the-economics-of-building-ml-products ↩
Zhang, J., Krishna, R., Awadallah, A. H., & Wang, C. (2023). EcoAssistant: Using LLM Assistant More Affordably and Accurately. University of Washington and Microsoft Research. Retrieved from https://arxiv.org/abs/2310.03046 ↩